4月21日,昆仑万维SkyReels团队正式发布并开源SkyReels-V2——全球首个使用扩散强迫(Diffusion-forcing)框架的无限时长电影生成模型,其通过结合多模态大语言模型(MLLM)、多阶段预训练(Multi-stage Pretraining)、强化学习(Reinforcement Learning)和扩散强迫(Diffusion-forcing)框架来实现协同优化。

回顾过去一年,视频生成技术在扩散模型和自回归框架的推动下取得了显著进展,但在提示词遵循、视觉质量、运动动态和视频时长的协调上仍面临重大挑战。
现有技术在提升稳定的视觉质量时往往牺牲运动动态效果,为了优先考虑高分辨率而限制视频时长(通常为5-10秒),并且由于通用多模态大语言模型(MLLM)无法解读电影语法(如镜头构图、演员表情和摄像机运动),导致镜头感知生成能力不足。这些相互关联的限制阻碍了长视频的逼真合成和专业电影风格的生成。
为了解决这些痛点,SkyReels-V2应运而生,它不仅在技术上实现了突破,还提供多了多种有用的应用场景,包括故事生成、图生视频、运镜专家和多主体一致性视频生成(SkyReels-A2)。
SkyReels-V2现已支持生成30秒、40秒的视频,且具备生成高运动质量、高一致性、高保真视频的能力。
核心技术创新,迈入“无限时长、影视级质量、精准控制”的全新视频生成阶段
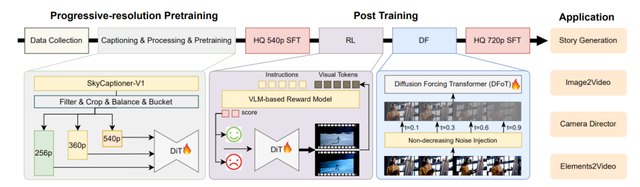
图丨SkyReels-V2方法概述
SkyReels-V2能够达到这样的视频生成效果,源于其多项创新技术:
1. 全面的影视级视频理解模型:SkyCaptioner-V1
为了提高提示词遵循能力,团队设计了一种结构化的视频表示方法,将多模态LLM的一般描述与子专家模型的详细镜头语言相结合。这种方法能够识别视频中的主体类型、外观、表情、动作和位置等信息,同时通过人工标注和模型训练,进一步提升了对镜头语言的理解能力。
同时,团队训练了一个统一的视频理解模型 SkyCaptioner-V1,它能够高效地理解视频数据,生成符合原始结构信息的多样化描述。通过这种方式,SkyCaptioner-V1不仅能够理解视频的一般内容,还能捕捉到电影场景中的专业镜头语言,从而显著提高了生成视频的提示词遵循能力。此外,这个模型现在已经开源,可以直接使用。
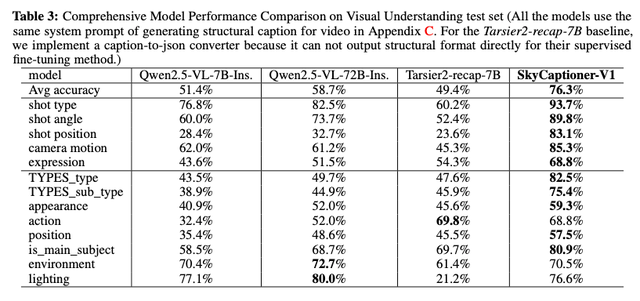
图丨在视频理解测试集上的模型综合性能比较中,SkyCaptioner-V1表现优异,超越了SOTA的模型。
2. 针对运动的偏好优化
现有的视频生成模型在运动质量上表现不佳,主要原因是优化目标未能充分考虑时序一致性和运动合理性。我们通过强化学习(RL)训练,使用人工标注和合成失真数据,解决了动态扭曲、不合理等问题。为了降低数据标注成本,我们设计了一个半自动数据收集管道,能够高效地生成偏好对比数据对。
通过这种方式,SkyReels-V2在运动动态方面表现优异,能够生成流畅且逼真的视频内容,满足电影制作中对高质量运动动态的需求。
3. 高效的扩散强迫框架
为了实现长视频生成能力,我们提出了一种扩散强迫(diffusion forcing)后训练方法。与从零开始训练扩散强迫模型不同,我们通过微调预训练的扩散模型,将其转化为扩散强迫模型。这种方法不仅减少了训练成本,还显著提高了生成效率。
我们采用非递减噪声时间表,将连续帧的去噪时间表搜索空间从 O(1e48) 降低到 O(1e32),从而实现了长视频的高效生成。这一创新使得SkyReels-V2能够生成几乎无限时长的高质量视频内容。
4. 渐进式分辨率预训练与多阶段后训练优化
为了开发一个专业的影视生成模型,我们的多阶段质量保证框架整合了来自三个主要来源的数据:
通用数据集:整合了开源资源,包括Koala-36M、HumanVid,以及从互联网爬取的额外视频资源。这些数据提供了广泛的基础视频素材,涵盖了多种场景和动作。
自收集媒体:包括280,000多部电影和800,000多集电视剧,覆盖120多个国家(估计总时长超过620万小时)。这些数据为模型提供了丰富的电影风格和叙事结构。
艺术资源库:从互联网获取的高质量视频资产,确保生成内容的视觉质量达到专业标准。
原始数据集规模达到亿级(O(100M)),不同子集根据质量要求在各个训练阶段使用。此外,我们还收集了亿级的概念平衡图像数据,以加速早期训练中生成能力的建立。在此数据基础上,我们首先通过渐进式分辨率预训练建立基础视频生成模型,然后进行四阶段的后续训练增强:
初始概念平衡的监督微调(SFT):通过概念平衡的数据集进行微调,为后续优化提供良好的初始化。
运动特定的强化学习(RL)训练:通过偏好优化提升运动动态质量。
扩散强迫框架(DF):实现长视频生成能力。
高质量SFT:进一步提升视觉保真度。
结合富含影视级别数据和多阶段优化方法,我们确保了SkyReels-V2在资源有限的情况下,高效的稳步提升多方面的表现,达到影视级视频生成的水准。
在SkyReels-Bench和V-Bench评估中,性能表现卓越
为了全面评估SkyReels-V2的性能,我们构建了SkyReels-Bench用于人类评估,并利用开源的V-Bench进行自动化评估。这种双重评估框架使我们能够系统地比较SkyReels-V2和其他最先进的基线模型(包括开源和闭源模型)。
1. SkyReels-Bench评估
SkyReels-Bench包含1020个文本提示词,系统性地评估了四个关键维度:指令遵循、运动质量、一致性和视觉质量。该基准旨在评估文本到视频(T2V)和图像到视频(I2V)生成模型,提供跨不同生成范式的全面评估。
在SkyReels-Bench评估中,SkyReels-V2在指令遵循方面取得了显著进展,同时在保证运动质量的同时不牺牲视频的一致性效果。具体表现如下:
指令遵循:SkyReels-V2在运动指令、主体指令、空间关系、镜头类型、表情和摄像机运动的遵循上均优于基线方法。
运动质量:在运动动态性、流畅性和物理合理性方面,SkyReels-V2表现出色,生成的运动内容自然且多样。
一致性:主体和场景在整个视频中保持高度一致,运动过程有较高的保真度。
视觉质量:生成视频在视觉清晰度、色彩准确性和结构完整性上均达到高水平,无明显扭曲或损坏。
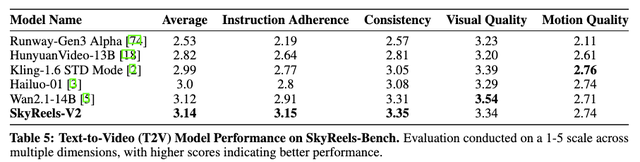
图丨在SkyReels-Bench的T2V多维度人工评测集下,SkyReels-V2在指令遵循和一致性得到最高水准,同时在视频质量和运动质量上保持第一梯队
2. VBench1.0结果
在VBench1.0自动化评估中,SkyReels-V2在总分(83.9%)和质量分(84.7%)上均优于所有对比模型,包括HunyuanVideo-13B和Wan2.1-14B。这一结果进一步验证了SkyReels-V2在生成高保真、指令对齐的视频内容方面的强大能力。
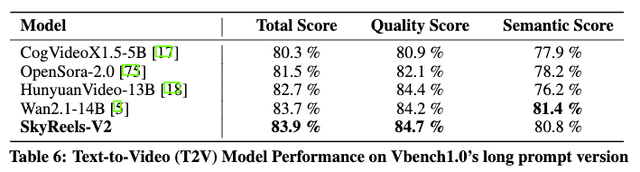
图丨在V-bench1.0的长prompt版本下,SkyReels-V2超越了所有的开源模型,包括HunyuanVideo-13B和Wan2.1-14B
03
丰富的应用场景,赋能创意实现
SkyReels-V2不仅在技术上实现了突破,还为多个实际应用场景提供了强大的支持:
1. 故事生成
SkyReels-V2能够生成理论上无限时长的视频,通过滑动窗口方法,模型在生成新帧时会参考之前生成的帧和文本提示。为了防止错误积累,我们采用了稳定化技术,通过在之前生成的帧上添加轻微噪声来稳定生成过程。这种方法不仅支持时间上的扩展,还能生成具有连贯叙事的长镜头视频。
通过一系列叙事文本提示,SkyReels-V2能够编排一个连贯的视觉叙事,跨越多个动作场景,同时保持视觉一致性。这种能力确保了场景之间的平滑过渡,使得动态叙事更加流畅,而不会影响视觉元素的完整性。这一功能特别适合需要复杂多动作序列的应用,如电影制作和广告创作。
2. 图像到视频合成
SkyReels-V2提供了两种图像到视频(I2V)的生成方法:
·微调全序列文本到视频(T2V)扩散模型(SkyReels-V2-I2V):通过将输入图像作为条件注入T2V架构中,模型能够利用参考帧进行后续生成。这种方法在384个GPU上仅需10,000次训练迭代即可取得和闭源模型同等级的效果。
· 扩散强迫模型与帧条件结合(SkyReels-V2-DF):通过将第一帧作为干净的参考条件输入扩散框架,无需显式重新训练即可保持时间一致性。
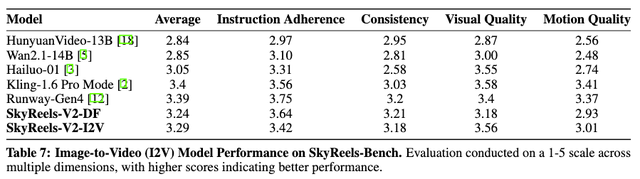
在SkyReels-Bench的I2V多维度人工评测集下,SkyReels-V2在所有质量维度上均优于其他开源模型,并与闭源模型表现相当。
3. 摄像导演功能
SkyReels-V2在标注摄像机运动方面表现出色,但我们发现摄像机运动数据的固有不平衡对进一步优化摄影参数提出了挑战。为此,我们专门筛选了约100万个样本,确保基本摄像机运动及其常见组合的平衡表示。通过在384个GPU上进行3,000次迭代的微调实验,我们显著提升了摄影效果,特别是在摄像机运动的流畅性和多样性方面。
4. 元素到视频生成
基于SkyReels-V2基座模型,我们研发了SkyReels-A2方案,并提出了一种新的多元素到视频(E2V)任务,能够将任意视觉元素(如人物、物体和背景)组合成由文本提示引导的连贯视频,同时确保对每个元素的参考图像的高保真度。这一功能特别适合短剧、音乐视频和虚拟电商内容创作等应用。
作为首个商业级E2V开源模型,SkyReels-A2在E2V评估Benchmark A2-Bench中的结果表明,其一致性和质量维度上评估与闭源模型相当。未来,我们计划扩展框架以支持更多输入模态,如音频和动作,旨在构建一个统一的视频生成系统,以支持更广泛的应用。
SkyReels-V2的推出标志着视频生成技术迈入了一个新的阶段,为实现高质量、长时间的电影风格视频生成提供了全新的解决方案。它不仅为内容创作者提供了强大的工具,更开启了利用AI进行视频叙事和创意表达的无限可能。
昆仑万维SkyReels团队仍致力于推动视频生成技术的发展,并将SkyCaptioner-V1和SkyReels-V2系列模型(包括扩散强迫、文本到视频、图像到视频、摄像导演和元素到视频模型)的各种尺寸(1.3B、5B、14B)进行完全开源,以促进学术界和工业界的进一步研究和应用。
节点声明:本内容为作者独立观点,不代表节点财经立场。未经允许不得转载,文中内容仅供参考,不作为实际操作建议,交易风险自担。